Post-mortem of the 1st of July outage

According to our mission, we are committed to transparency and accountability. This post-mortem is part of that commitment, detailing the events surrounding the outage of the 1st of July 2025.
Summary of the impact
We experienced a significant outage on the 1st of July 2025, which affected our services for approximately 6 hours. During this time, users were unable to validate their pincodes and access their Yivi App, making the Yivi-App unusable. The issue was caused by an outage in the Scaleway data center AMS-1, where our database server is located. Scaleway preemptively shut down several services in the datacenter to prevent further issues such as hardware damage due to abnormal temperatures.
Timeline of the incident
| Date & Time | Description |
|---|---|
| July 1st, 2025, 16:30 CEST | Scaleway confirmed that they were experiencing issues due to abnormal temperatures in the data center AMS-1 |
| July 1st, 2025, 16:45 CEST | Our database server started spiking CPU usage and Total Connection, successively Scaleway preemptively shut down several services in the datacenter, to prevent it from further issues such as hardware damage. |
| June 1st, 2025, 16:57 CEST | Received a first report from a user that the user received errors validating the pincode in the Yivi app. |
| July 1st, 2025, 17:00 CEST | Started investigating the issue and found that the database server was experiencing high CPU usage. |
| July 1st, 2025, 17:10 CEST | Confirmed that the issue was caused by Scaleway, our infrastructure provider. |
| July 1st, 2025, 17:30 CEST | Restarted the Keyshare backend services to try to restore the database connections. |
| July 1st, 2025, 18:00 CEST | Started configuring a failover database server, for whenever the issue was not fixed over night. |
| July 1st, 2025, 23:25 CEST | Scaleway's Infrastructure provider resolved the issue, restarted the services and our system recovered accordingly. |
See the full incident report from Scaleway for more details: Scaleway Status Page
Below are the metrics from the database server that show the CPU usage and Total Connections were spiking prior to the downtime.
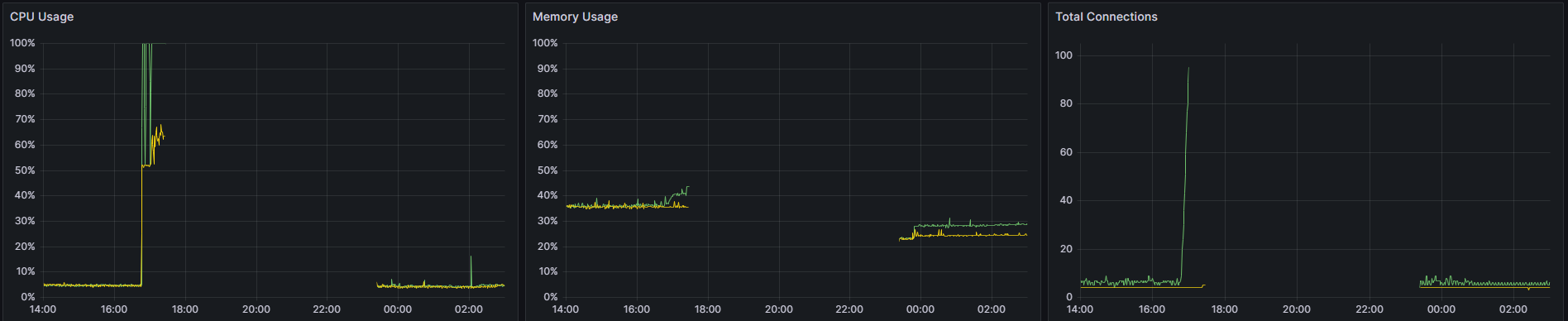
Customer impact
Users were unable to validate their pincodes and access their Yivi App during the outage. The impact was significant, as users were unable to use the app for approximately 6 hours.
Root cause and mitigation
Yivi uses Scaleway as its infrastructure provider, and the outage was caused by an issue in their data center AMS-1. The issue was due to abnormal temperatures in the data center, which led to Scaleway preemptively shutting down several services to prevent further issues such as hardware damage. Temperatures in the Amsterdam area were unusually high, the infrastructure cooling system couldn't keep up, which caused the data center to overheat.
An availability zone is a distinct location within a data center region, designed to be isolated from failures in other availability zones. This setup allows for high availability and fault tolerance.
Yivi uses a multi-availability zone setup, which means that if one availability zone goes down, the other availability zone can take over. We use this for our Kubernetes cluster, which is responsible for running the Yivi backend services, including the Keyshare backend services, serveral issuers, the portal, etc. This setup allows us to ensure high availability and fault tolerance for our services.
However, our database server which is configured as a High Availability (HA) database within Scaleway, was located in the affected data center. This meant that when Scaleway shut down the services in that availability zone, our database server was also affected, leading to the outage. As a team we were expecting that the failover database server would be automatically used, but this was not the case, apparently both of the racks that power our database server were affected by the outage.
Scaleway documentation Are my active and standby database nodes in a high-availability cluster hosted in the same data center? In a high-availability cluster, active and hot standby nodes are indeed located in the same data center but in two separate racks. The idea is to offer the best performance to our users by reducing latency between active and hot standby nodes, as we use a sync replication process between the nodes.
Next steps
We think that the best way to prevent this issue from happening again is to create an additional failover database server in a different availability zone or even on a different infrastructure provider. This way, if one availability zone goes down, the failover can take over and the database server will still be available. This is not a native feature of the Scaleway Managed Database service, so we will have to implement this ourselves. Our Kubernetes cluster is already set up to use multiple availability zones and during this issue the 2 other nodes in the cluster were still operational, servicing traffic and requests, but the database server was not available, which caused the outage.
Next to that we indentified the following next steps aswell:
- If one of the nodes powering the kubernetes cluster goes down, the other nodes will still be operational. However if for some reason we want to change the configuration of for instance the keyshare server to point to a different database then we can't do that with Terraform since its blocks on shutting down pods that run on unavailable nodes. Leaving us with no way other then to manually change the configuration of the keyshare server, which is not ideal.
- The Scaleway Managed Database service always for a ReadOnly replica which can be promoted to a primary database server. However, this is not automatically done in case of an outage, so we will have to implement this ourselves as well. This means that we will have to monitor the database server and if it goes down, we will have to promote the ReadOnly replica to a primary database server.
- Our blog also runs on the same Scaleway infrastructure, which we couldn't update because the Terraform changes were blocked by the unavailable nodes in the Kubernetes cluster. This means that we couldn't update our blog to inform users about the outage and the progress we were making to resolve it. We will have to implement a way to update our blog in case of an outage, so that we can keep our users informed.
- Our public website has to incident page that informs users about the outage and the progress we are making to resolve it. This page should be accessible even if the blog is down, so we will have to implement this as well.
- We have no mechnism in place to inform users in the Yivi-app about the outage or scheduled maintenance. We will have to implement a way to inform users about the outage or scheduled maintenance, so that they are aware of the situation and can take appropriate action.